De l’usage approprié du netlinking dans la SEO organique
Sommaire

Dans l’absolu, un réseau de liens sur le web issu d’une campagne de netlinking va ressembler à un réseau neuronal humain
Nous voyons souvent des clients consulter des agences de Netlinking ou SEO et réclamer d’emblée d’obtenir des liens pour une meilleure visibilité organique. Et hélas nombre d’agences SEO proposant du netlinking, servent le client à la demande, en-veux-tu en-voilà de la campagne de netlinking, sans se poser la question de savoir si le client est légitime sur sa thématique, s’il ne traîne pas déjà un casier judiciaire off-page, et si le on-page est digne de recevoir de tels signaux.
Pourquoi une telle mise en garde ? Eh bien, car les liens sont parmi les facteurs pénalisants dont il est le plus difficile de s’en remettre. On peut corriger les erreurs et errements on-page et obtenir le pardon de Google à court ou moyen terme. Mais des liens jugés toxiques par l’algorithme, peuvent condamner un nom de domaine à jamais ! J’ai personnellement vu des un site ayant trusté la positon numéro 1 pendant 3 ans (un client hanoot) sur la cigarette électronique avoir été cramé en une nuit par une campagne de netlinking en negative SEO, ayant permis d’émettre des millions de liens issus de Russie et autres paradis du spam sauvage. Google n’y a vu que du feu, et a divisé le trafic organique du site par 15 en quelques jours … Nous allons examiner ci-après les signes d’un bon et d’un mauvais netlinking.
Critères officiels de Google pour évaluer la qualité d’un netlinking
Dès la fin de l’année 2003, Google a déposé un brevet qui rassemble la majorité des signaux de pondération d’un netlinking. Ce brevet n’a été rendu public qu’en mars 2005 ! Dans ce brevet fondamental, Google fait un parallèle entre la naissance et la croissance d’un site web par rapport à la courbe de croissance d’un être humain. A un instant T , un site normal, non boosté aux stéroïdes, a une voilure et un carnet de relations ( comprenez signaux entrants) proportionnels à son âge, sa notoriété et sa taille. Le brevet est consultable ici,
et porte en descriptif liminaire cette mention :
Récupération d’informations basée sur des données historiques
Résumé :
Un système identifie un document et obtient un ou plusieurs types de données historiques associées au document. Le système peut générer un score pour le document sur la base, au moins en partie, du ou des types de données historiques.
Pour une version simplifiée proposée par rankspirit
Parmi les critères concernant les liens ou netlinking et abordés dans ce brevet nous relevons que :
- L’indexation des url est horodatée . La date de naissance d’une page est le moment ou Google indexe la page en question. Cette donnée va influer sur la perception des liens que nous verrons plus loin.
- Google avait déjà acté la notion de « DA » ou Domain Authority dès 2003 puisqu’il stipule dans ce breve,t qu’ un site jeune a proportionnellement moins de liens entrants qu’un site plus ancien. Le pagerank porte en lui une pondération liée à l’âge du domaine et de chaque page du site.
- La vitesse d’acquisition des liens à un instant donné peut être un facteur encore plus déterminant que le nombre de liens lui-même.
Ce point est important car nous constatons que Google l’utilise pour qualifier les liens toxiques qui apparaissent comme des crises d’urticaire, ou au contraire, détecter des signaux positifs liés à une marque, un événement, une actualité chaude, un personnage en vogue. Cet aspect est devenu encore plus prégnant à l’ère des réseaux sociaux. - La date à la quelle des liens apparaissent et disparaissent, c’est à dire leur durée de vie, ou persistance, la fréquence avec laquelle ces événement surviennent , sont des signaux qui entrent en compte dans la qualification des liens
- L’amplitude à un instant T de la création des liens pointant un document peut être un facteur positif
- L’âge des liens et leur évolution renseigne Google sur la typologie et qualité du site web qui héberge le document bénéficiant de ces liens entrants
- Les liens d’un document qui a été édité et réédité et qui résistent à ces mises à jour en étant toujours présents das le corps du document, se voient grandement valorisés
- Des liens nouveaux ou récents qui pointent un document ancien , non mis à jour, permettent à ce document d’être considéré par Google comme encore pertinent
- L’apparition de rapide de nombreux liens issus de référents gratuits, genre annuaires ou blogs publics, peut pénaliser la page ou le site web qui en bénéficie
- De même une hémorragie de liens vers une page peut signifier que le document n’est plus d’actualité
En aout 2010 , Google récidive et obtient publication d’un autre brevet déposé en 2004. Le brevet est libellé : « Determining quality of linked documents » et que l’on peut traduire par : De la détermination qualitative de documents liés.
Dans ce brevet Google détaille les signaux qui lui permettent de détecter les liens de complaisance à contrario des liens spontanés et organiques. Dans sa traque et détection des liens de complaisance ou achetés, Google analyse le degré de proximité du site ou de la page émettrice et de la page qui reçoit le lien. Pour cela il a recours à des notions comme la propriété des sites émetteur et récepteur, l’hébergement et les IP du site site émetteur et récepteur, la direction des liens croisés, pyramidaux et circulaires.
Les liens nombreux émanant d’un même domaine sont dévalorisés. Les liens issus de zones de templates respectives, (footer, widgets). Les sites très interconnectés voient le poids de leur liens revu à la baisse.
Voir cette vidéo ou John Mueller explique sa vision des liens qui interconnectent le web.
Pour mettre ses préventions en accord avec ses actions, Google a frappé très fort à travers une mise à jour importante de son algorithme nommé penguin, survenue le 24 avril 2012 et qui a marqué une génération de SEO. Une partie de cet algorithme visait les liens de piètre qualité ou spammy. Il a été dit clairement par l’équipe de Google, que la mise à jour avait dans son viseur le netlinking de mauvaise qualité. c’est-à-dire, et entre autres, les liens ayant des ancres sur-optimisées, ou encore des ancres toujours similaires, des liens issus de sites sans colonne vertébrale éditoriale, les liens en provenance des annuaires ou des Communiqués de Presse, car il faut se souvenir à quoi ressemblait le web à cette époque ; des annuaire et des pseudo communiqués de presse à tire-larigot. La belle époque révolue pour certains nostalgiques…
Mais Google est revenu à la charge avec Penguin le 23 septembre 2016, avec une version 4.0 dite temps réel, ce qui signifie que le filtre anti liens de spam fonctionne en continu et en temps réel dans l’algorithme, alors que jusque là il fonctionnait uniquement lors des déploiements occasionnels. Cette mise à jour de penguin avait été annoncée 13 mois plutôt puis reportée pour des tests plus poussés, signe de la complexité et de la sensibilité de cette mise à jour de l’algorithme, et comme quoi Google y attache une importance certaine. Cette mise à jour vient confirmer ce que l’on savait déjà des mauvaises pratiques dans les campagnes de netlinking, à savoir que :
- Liens sitewide dofollow en footer, sidebar, widget avec des ancres optimisées
- Plusieurs liens dofollow avec des ancres optimisées depuis une seule page vers le même site
- Des liens en signatures de forums avec des ancres optimisées et dofollow
- Des liens dofollow avec des ancres optimisées depuis des annuaires dédiés au SEO
Quels sont les signes distinctifs d’un mauvais netlinking ?
Les remarques ci dessous proviennent de la pratique et expérience de hanoot dans les profils de liens observés chez les clients pénalisés.
- Un site non multilingue qui se retrouve avec des liens en provenance des 5 continents et depuis des pages dont la langue est différente du site cible.

On voit clairement que les pays émetteurs n’ont aucun rapport avec la langue ni la culture locale du site. Exemple typique d’une campagne de netlinking spammy
- Des liens qui augmentent et baissent sans raison objective de manière flagrante.

au vu de telles courbes de liens, google ne peut que sanctionner la campagne de netlinking sauvage et toxique. Dire que le client a payé pour se suicider…
- Des liens avec des ancres trop parfaites
- Un pourcentage élevé d’ancres parfaites
- Des liens trop nombreux acquis juste après la mise en ligne d’un site
- Des liens croisés, circulaires, pyramidaux ou issus de sites satellites. A ce sujet, regardez cette vidéo, qui traite du point épineux de l’achat ou non de liens via des agences de netlinking spécialisées dans la vente de liens « en gros » .
- Des liens issus d’annuaires et de fermes à liens

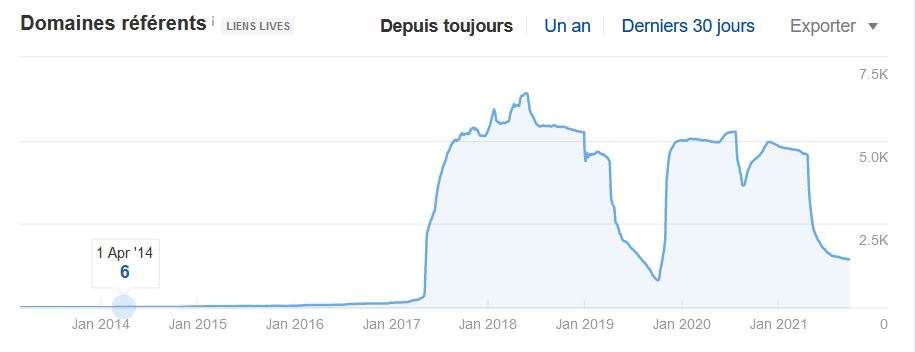
Des outils permettent de contrôler la qualité de son netlinking
Pour les outils du commerce, qui servent entre autres à nous renseigner sur le profil de liens d’un site, Nous citerons :
AHREFS – MAJESTIC – SEMRUSH. Un article à venir sur ces outils est en cours de réparation. À cet égard l’équipe de semrush france a publié une vidéo qui explique , selon eux, comment doit se construire une campagne de netlinking.
Dans le cas de la détection de liens toxiques, Google via sa search console, met à disposition des éditeurs de sites, un outil pour désavouer des liens jugés toxiques. Attention cette action ne supprime par les liens dénoncés ou désavoués, elle dit juste à Google de ne pas les prendre en compte et Google avertit qu’il n’est pas tenu de suivre les instructions du fichier que l’usager lui transfére. Le lien vers l’outil se trouve ici, il faut bien sur être connecté a son compte google search
https://search.google.com/search-console/disavow-links
la syntaxe est la suivante :
pour désavouer tous les liens en provenance d’un domaine D
domain:nom-de-comaine-desavoue.com
pour désavouer une page en particulier, il suffit de coller son url à la ligne suivante :
https://www.url-de-la-page-distante
le document doit être un document txt réalisé sur bloc-note. Chaque ligne contient une instruction différente. Mais ne vous inquiétez une fois chargé, Google se charge de dédoublonner le document et vous signale les erreurs de syntaxe éventuelles avec précision.
Toute la procédure est expliquée ici :
et voici une vidéo qui donne une aperçu de la façon dont on peut analyser un profil de liens entrants :
Comment reconnaître une agence faisant du bon netlinking ?
- l’agence ne déclenche pas d’opération de netlinking sans avoir ausculté , et réparé le code si déficient
- l’agence ne fait pas de netlinking si le contenu du site est pauvre ou illégitime
- l’agence travaille d’abord le maillage interne ou le linking interne au site
- l’agence ausculte la concurrence pour se situer dans la moyenne qualitative des sites positionnés. Dans cette video John Mueller , ingénieur chez Google explique comment il faut se focaliser plutôt sur la qualité des liens que leur quantité.
- l’agence respecte une courbe d’acquisition réaliste et organique via une pente alpha qui ne dépareille pas par rapport à la concurrence
- l’agence évite les liens issus de pages en langues tierces
- l’agence fuit les annuaires folkloriques
- l’agence évite les ancres trop parfaites ou sur-optimisés
- l’agence évite les liens depuis les zones de template repetitives
- l’agence évite les échanges de liens
- l’agence promeut en premier les url des pages déjà positionnées même mal classées
- l’agence ne pointe pas seulement la page home mais alimente également en liens les pages de second niveau dites pages profondes>
- l’agence ne travaille avec avec des vendeurs de liens notoires ou connus comme tels. Voir à ce sujet la vidéo sur les réseaux de liens et les PBN.
- Liste non exhaustive ….
Théories et concepts avancés de netlinking
Voici à présent, des développements plus techniques et ardus, pour les experts qui s’intéressent au concept. certaines affirmations sont totalement originales et issues de la technologie hanoot.
Le Netlinking, ou le péché originel de l’algorithme de Google
Ah les liens, les fameux liens, ou maudits liens (c’est selon), le netlinking, le linkbait, , ou encore les BL ( BackLinks) pour les intimes …. Ces mots exercent, et ont exercé depuis les origines, une absolue fascination sur l’expert et le profane. Ils inspirent une vénération quasi magique à ceux qui considèrent le web comme une opportunité facile de gain à tout prix, et malheureusement l’espèce humaine étant ce quelle est, la manipulation frauduleuse des BL, l’intention de nuire à autrui et a fortiori aux concurrents, ont attiré les plus gros contingents de pratiques délictuelles. On parle de Black Hat, même si ce terme est souvent bien galvaudé
Nous disions en titre que la malédiction du lien , du Netlinking, du linkbait est le péché originel de Google. Car ce concept est à l’origine même de la naissance du moteur Google et de son essor. Et malgré les progrès apparents du moteur de recherche dans la compréhension pointue du sens, sa pondération et la multiplication des signaux transversaux de valorisation des contenus et leurs classement dans les SERP, ces fameux liens demeurent encore et toujours à ce jour, une composante déterminante dans le ranking des résultats de recherche organiques. Pour comprendre pourquoi Google traîne ce péché original (comme un boulet il le reconnaît lui-même), il faut remonter aux origines théoriques fondamentales du moteur de recherche, tel qu’il a été mis au point par ses créateurs Larry Page et Sergey Brin, qui ont accumulé en passant, une fortune colossale .
Google a fait des tests pour se passer des liens dans ses calculs de ranking, et il s’est avéré que les résultats étaient décevants, le taux de spam dans els SERP remontait en flèche.
A l’origine du noyau de Google fut le Netlinking, le BL bref le LIEN
Cet article est issu des travaux de hanoot.
Le brevet du pagerank a été déposé le 1er septembre de l’an 1998. Voir le document ici.
dans son descriptif, il était dit ceci : ( lecture indigeste, on vous prévient) :
Méthode de classement des nœuds dans une base de données liée
Résumé :
Un procédé attribue des rangs d’importance à des nœuds dans une base de données liée, telle qu’une base de données de documents contenant des citations, le World Wide Web ou toute autre base de données hypermédia. Le rang attribué à un document est calculé à partir des rangs des documents le citant. De plus, le classement d’un document est calculé à partir d’une constante représentant la probabilité qu’un navigateur passant par la base de données accède au document de manière aléatoire. Le procédé est particulièrement utile pour améliorer les performances des résultats des moteurs de recherche pour les bases de données hypermédias, telles que le World Wide Web, dont les documents présentent une grande variation de qualité.
Notre postulat est que le Page Rank survit dans le noyau de Google, mais de manière plus complexe et fine… La simplification du modèle originel de HITS dans le modèle du PR, conjuguée au contexte commercial et concurrentiel du web, ont abouti à ces dérives que l’on connaît, et qu’a essayé de corriger 12 ans plus tard la couche dite Penguin annoncée par Google officiellement le 24 avril 2012.
Le génie hors-sol et sans filiation n’existant pas, en janvier 1996, les pères du PageRank et de Google, deux doctorants de l’université de Stanford, (usa), Sergey Brin et Larry Page se basent pour concevoir leur moteur de recherche Google, sur les travaux d’un immense mathématicien, Jon Kleinberg, qui a inventé pour IBM un algorithme portant l’acronyme HITS pour Hyperlink Induced Topic Search. L’algorithme HITS s’est construit à partir du Graphe du web.
Mais qu’est ce que le Graphe du web ?
Ce modèle mathématique essaye de nous montrer à quoi peut ressembler le web. Les mathématiciens se passionnent pour la modélisation de l’espace du web comme les astrophysiciens ont à cœur de dessiner le cosmos ! Mais le cosmos est une entité (en partie?) physique, le web est totalement virtuel. Seuls des modèles mathématiques puissants peuvent en donner une idée.
Il existe trois modèles qui essayent de formaliser le web :
1- un modèle macroscopique
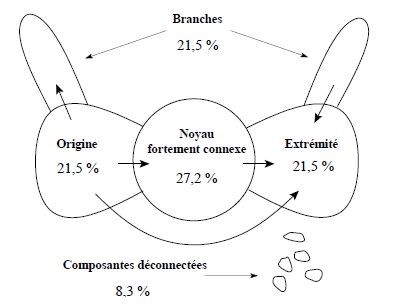
Modélisation théorique du graph du web sous forme de nœud papillon
où l’espace web serait composé de quatre zones distinctes :
Un gros noyau depuis lequel on peut aller de n’importe quelle page vers n’importe quelle autre en suivant des liens.
Un deuxième ensemble de pages depuis lesquels on peut aller dans le noyau, mais sans liens retour depuis ce noyau
Le troisième ensemble de pages est présent dans le noyau, mais ne renvoie pas vers le noyau
Un grand nombre de pages qui ne permettent pas d’atteindre le noyau et auxquelles le noyau ne permet pas d’accéder. Une espèce de nos mans land …
La modélisation numérique a fait dire aux chercheurs que c’était un modèle en nœud papillon.
Ce modèle a mis fin à la croyance que l’on pouvait atteindre toutes les pages du web depuis n’importe quelle page en suivant les liens.
2-Le modèle microscopique :
Ce modèle s’intéresse aux petits ensembles comme ceux qui agrègent une communauté.
3-Le modèle statistique
Ce modèle dessine le web à travers le nombre de liens sortants d’une page, le nombre d’images qu’elle peut contenir, la taille en poids des pages. Ce modèle estime qu’une page contient en moyenne 11 liens, et qu’une grande majorité des pages n’est pas liée. Que le nombre de pages ayant 9 liens est 5 fois moindre que les pages ayant un seul lien …
Voici à quoi peut ressembler un modèle dit particulaire pour illustrer le Graphe du web :

L’algorithme HITS (d’où est issu le PageRank), stipule que tous les sites Web n’ont pas la même importance, et ne jouent pas le même rôle. ( voir à cet égard l’article, segments et finalités
Et également ce texte.
Netlinking : sites pivot, sites relais et autorité
Il y a les sites qui font autorité ( authorities ) en fait ceux qui contiennent la véritable source d’ information originale et faisant référence.
En second il y a les sites relais, qui ne contiennent pas à proprement parler d’information, mais aiguillent vers les sites de références. On les appelle HUB, ou sites PIVOTS ou sites RELAIS.
On peut schématiser ces deux ensembles par la vue suivante :
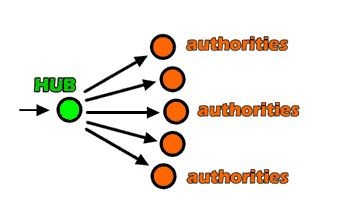
Les entités représentatives dans le netlinking et l’autorité, les pivots et les relais
Si vous remarquez bien dans les résultats de SERP, en première page, Google affiche de plus en plus ces deux entités !
Vous allez trouver par exemple des comparateurs ou des guides de consommateurs qui renvoient vers de grandes Market places au détriment des petits sites e commerce.
Un pivot possède de nombreux liens sortant pointant vers les autorités, et les autorités sont caractérisées par de nombreux liens entrant venant des pivots.
L’analyse des pivots et autorités permet ainsi de distinguer l’existence de communautés. C’est l’un des avantages du HITS par rapport au PageRank, qui ne permet pas de repérer les communautés aussi facilement.
Plus la requête de l’usager est large dans sa formulation, et plus le nombre de réponses possibles augmente, c’est à ce moment là qu’intervient le plus le principe d’autorité pour faire le tri dans la masse des réponses possibles.
Quand l’usager formule une requête plus précise, l’algorithme va « piocher » dans un sous graphe déjà identifié avec des ensembles de pages où préfigurent des pages d’autorité au niveau du sous ensemble. Il est à considérer, fait intéressant, que dans ce sous graphe, l’algorithme va tenir compte des liens sortants, appelés liens transverses puisque les autorités sont absentes de ce sous graphe. Mais, les liens de navigation proprement dits, appelés liens intrinsèques, sont traités en bruit de fond et éliminés de ce sous graphe ! Selon le même principe sont supprimés de ce sous graphe, les liens publicitaires ! Sont supprimés également les citations en footprint du type : ce site est fièrement propulsé par .. ou bien ce site a été conçu par … Mauvaise nouvelle pour les furieux des back links faciles en footer, ou en toute zone de template répétitive comme les widgets.
Ce constat renforce le principe que des liens contextualisés en cœur de page sont les seuls à même de transporter ou transmettre de la légitimité.
Les pages PIVOT jouent un grand rôle dans le calcul de pertinence d’une page. Car les pages faisant autorité sont pointées par de très nombreux pivots.
Pour le calcul itératif de l’algorithme, on affecte un poids de page PIVOT PP et un poids de page autorité PA. Les pages les plus puissantes sont celles qui cumulent les plus grandes valeurs de PA et PP !
Les moteurs de recherche utilisent la structure orientée du Graphe du web.
Le PageRank Google, se base sur le rang des pages, qui correspond à l’importance relative de chaque page du Web. Pour Google, même si un site web possède une note qualitative globale, le calcul du PageRank s’effectue url par url. Les limites du PageRank se voient dans son incapacité à découvrir des pages qui sont des « autorités » dans certains domaines particuliers, notamment les segments thématiques qui ne sont pas grand public.
La différence fondamentale entre le modèle de HITS et le PageRank est que dans le PageRank, Google assigne une valeur absolue à la page P et cette valeur n’est pas déterminée par une requête !
A l’époque où Google affichait la valeur du PR sur les navigateurs, je voyais souvent une valeur très importante pour la page contact par exemple ! ou pour des pages n’ayant pas de valeur en termes de caution intellectuelle ou de finalité de segment.
L’algorithme père, HITS classifie les pages importantes comme les pages faisant autorité. C’est un algorithme très puissant qui meut un moteur de recherche destiné à des fins industrielles. Sa pertinence semble être au dessus de celle du PageRank. Le poids d’une page est recalculé pour chaque requête ! C’est beaucoup plus précis mais infiniment plus gourmand en ressources.
C’est en partie, cet algorithme qui meut l’outil du spécialiste de l’intelligence économique, Factiva
et qui s’appuie sur les technologies d’extraction et d’analyse sémantique d’IBM pour traduire l’évolution de l’image des sociétés sur le web.
La force des liens dans le positionnement est avérée et voici un exemple issu de notre industrie et savoir-faire sur Monazina et hanoot :
Cartographie du netlinking ou liens entrants pour un site de référence
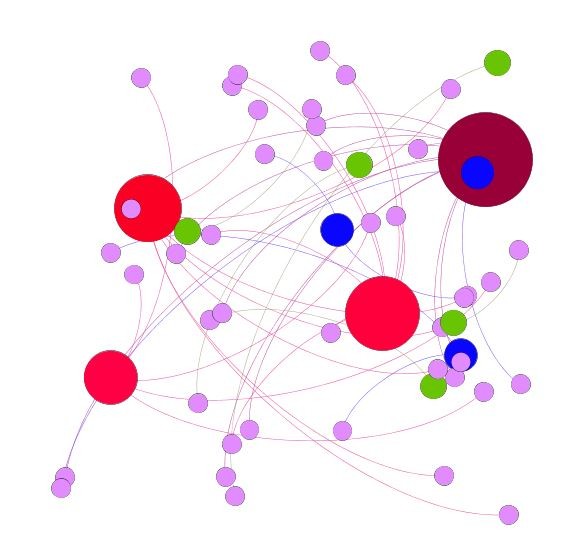
Voilà à quoi peut ressembler un réseau de liens issu d’une campagne de netlinking particulièrement efficace grâce à l’agence de netlinking hanoot.
Pour cette démonstration, issue des travaux de hanoot, il nous fallu un site de référence, de taille modeste, mais faisant autorité, afin que sa modélisation ne nécessite pas Big Blue … mais le portable de votre serviteur.
Dans cet article nous allons voir quelque chose d’inédit à mon sens. Nous allons visualiser à quoi ressemble le netlinking externe d’un site qui déchire tout dans sa catégorie.
Ce site se classe premier sur quasiment tous les syntagmes de son segment de finalité, dans un segment concurrentiel qui plus est … dans un pays voisin, la Suisse. J’ai été le seul à travailler la seo de ce site depuis l’origine, et il a acquis ce que j’appelle l’état de génération spontanée de signaux externes de qualité. Il est utile de signaler que le client n’a jamais joué à l’apprenti sorcier, comme font certains, grisés par l’ascension, il a écouté les conseils et n’a jamais joué avec le feu de la seo du dimanche … Le site ne traîne aucune casserole, ou casier judiciaire, comme j’aime à les nommer.
Le ratio liens-entrants / domaines émetteurs est de 12,6 ce qui est excellent, vu que la moyenne des concurrents se situe à 90.
Cela peut sembler incroyable, mais la moitié des pages du site ont entre 3 et 13 liens entrants issus de domaines émetteurs distincts !
La figure suivante montre le nombre de lies entrants par url classés par multiples de 5.

rations de Netlinking :Répartition des liens entrants par URL. Tout le site est irrigué de liens manière proportionnelle.
Les domaines qui émettent vers ce site ont tous du trafic organique, la part des domaines ayant un trafic organique nul est minoritaire, soit 12,5% des domaines. Donc un bouquet de domaines présentant une diversité « biologique » naturelle, sans aucun domaine spammy.
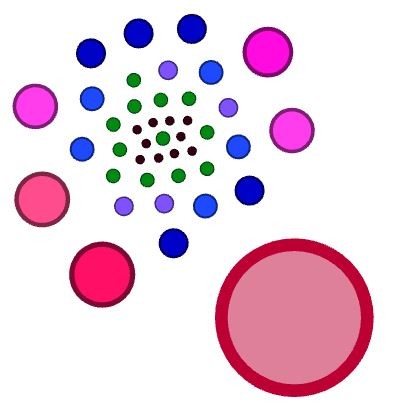
Cartographie du netlinking montrant à quoi ressemblent les paquets de liens entrants par types d’url
La galaxie des des urls recevant les liens entrants est harmonieuse. On distingue 5 niveaux d’autorité, pour tout l’index du site, la page home et les catégories principales étant les plus fortes.
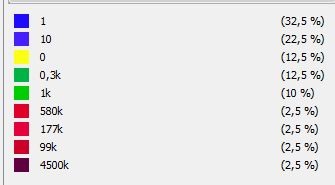
Tous les domaines émetteurs qui participent au netlinking ont du trafic organique et ne sont pas des sites artificiels.
Galaxie des domaines émetteurs vers le site et granulométrie de leur trafic organique
Pour ce dernier article , Références bibliographiques :
Notes de cours (ENS Lyon, M1) – Chapitre 3 : Reseaux sans fil
Le graphe du web, J.L. GUILLAUME et M. LETAPY
Fabien de Montgolfier – LIAFA, Universit´e Paris 7, France – Projet Algo – 31 janvier 2005
webmaster-hub













