La compréhension du langage naturel, par les algorithmes de Google, ne fut pas une mince affaire. Google a toujours essayé de dépasser la compréhension simpliste du langage à base d’une succession non interactive et décontextualisée, de mots clefs.
L’obsession des ingénieurs de Mountain View, a toujours été de contextualiser les mots et de comprendre les relation biunivoques qu’ils entretiennent entre eux dans une phrase, ceci afin de mieux cerner l’intention de l’usager et d’y répondre de manière plus satisfaisante, mais aussi de se prémunir contre les manipulations de l’algorithme par les furieux primaires des mots clef, du spin et autres facéties de la SEO bas de gamme.
Mais à ce jour, les ressources matérielles et intellectuelle pour relever ce défi titanesque, qui revient ni plus ni moins, pour Google, à lire et comprendre le langage écrit (presque) comme un humain, faisaient défaut. L’essor du Big Data, les investissement colossaux de Google, dans le secteur de l’intelligence artificielle via sa maison mère, devenue désormais alphabet ( cela veut tout dire ) ont rendu l’exploit possible et à portée de main. Et c’est au cours de la grand-messe auto promotionnelle de Google de cette année, le IO 2021 présentée ici par le président , Sundar Pichai, CEO de Google et Alphabet, que Google a dévoilé au monde son nouveau modèle de traitement complexe du langage baptisé MUM comme, modèle multi-tache unifié. Il faut préciser que MUM n’est toujours pas actif à ce jour au niveau de SERP c’est-à-dire au niveau des résultats de recherche de Google. Il est toujours en phase expérimentale. Son prédécesseur BERT, déployé en France en décembre 2019 et actif dans les SERP, bien que infiniment moins puissant que MUM , fut une avancée majeure pour Google dans le traitement du langage parlé et d’une approche plus fine de l’intention usager à travers sa requête.
Les prémisses conceptuelles de MUM depuis le modèle originel nommé BERT
Sommaire
BERT est une couche algorithmique basée sur un réseau neuronal pour le traitement du langage naturel (PNL) qui a été pré-formée sur le corpus Wikipédia. L’acronyme complet lit « Bidirectional Encoder Representations from Transformers » (les représentations d’encodeur bidirectionnel des transformateurs.). C’est un algorithme d’apprentissage automatique censé apporter une meilleure compréhension des requêtes et du contenu.
La chose la plus importante à retenir est que BERT utilise le contexte et les relations de tous les mots d’une phrase, plutôt qu’un mot après l’autre dans leur ordre d’apparition. Ainsi, BERT peut comprendre le contexte complet d’un mot en analysant les mots qui viennent avant et après. La partie bidirectionnelle de celui-ci rend BERT unique.
En appliquant cela, Google peut mieux comprendre l’essentiel d’une requête. Google a publié plusieurs exemples de requêtes dans le billet de blog de lancement.
BERT prend TOUT en compte dans la phrase et en découvre ainsi le vrai sens.
Un exemple concret :
- “2019 brazil traveler to USA need a visa” (“2019 un voyageur Brézilien a besoin d’un visa pour se rendre aux USA”)
Maintenant Google est capable de repérer le mot “to” et de comprendre qu’il s’agit d’un Brésilien souhaitant se rendre aux USA. Autrefois Google ne comprenait pas l’importance de cette connexion et pouvait renvoyer des résultats au sujet de citoyens Américains voyageant au Brésil, la réponse sera donc non adaptée à la requête.
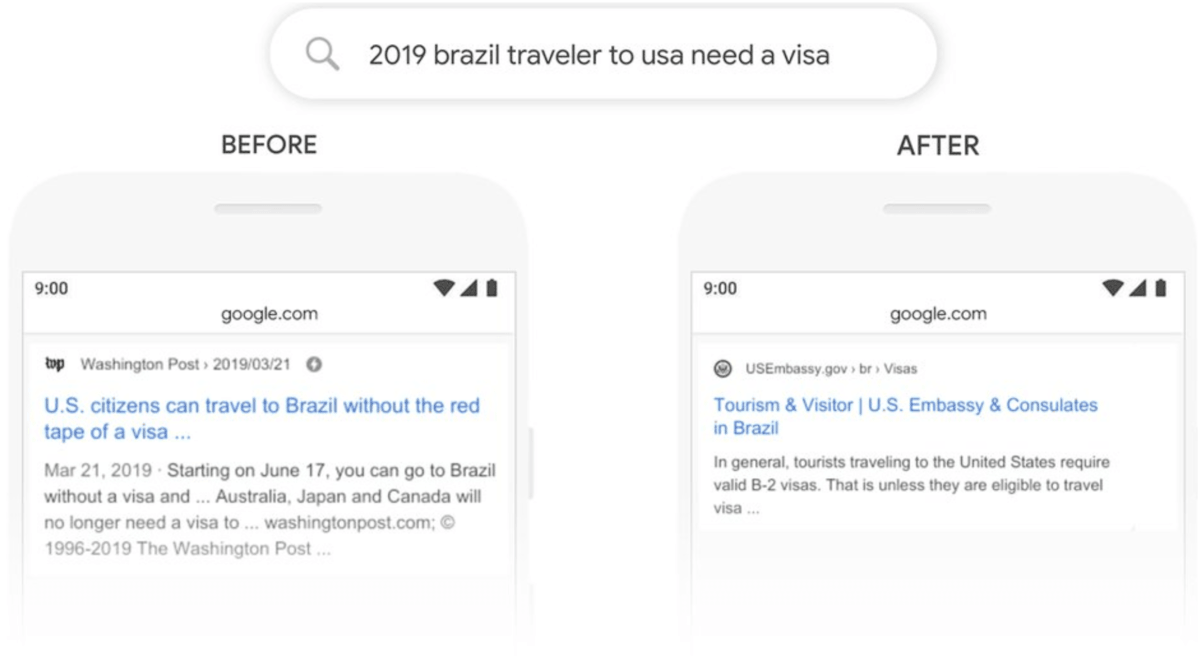
Exemple concret Google Bert
Comme vous pouvez le voir dans l’exemple, BERT fonctionne mieux dans les requêtes plus complexes. Ce n’est pas quelque chose qui intervient lorsque vous effectuez une recherche à partir des termes principaux, mais plutôt des requêtes dans la longue traîne. Pourtant, Google affirme que cela aura un impact sur toutes les recherches sur dix. Et même dans ce cas, Google dit que BERT se trompera parfois. Ce n’est pas la solution ultime à la compréhension des langues.
- Dernière mise à jour de Google: BERT
Les enseignements les plus importants de cette mise à jour de BERT sont que Google se rapproche encore une fois de la compréhension du langage au niveau humain. Pour les classements, cela signifie qu’il présentera des résultats qui correspondent mieux à cette requête et qui ne peuvent être qu’une bonne chose.
Il n’y a pas d’optimisation pour BERT autre que le travail que vous faites déjà: produire un contenu pertinent d’excellente qualité.
Le document original de BERT (pdf) contient tout ce dont vous avez besoin pour comprendre comment BERT fonctionne exactement. Malheureusement, c’est très savant et la plupart des gens ont besoin d’une «traduction».
Vidéo complète du webinaire
Qu’est-ce que MUM: Multitask United Model?
Le brevet déposé par Google le 19 mars 2020, aux USA, porte ne le numéro US20200089755A1
( Voir PDF complet du brevet en Anglais).
Google définit ainsi son projet dans sa présentation liminaire absolument illisible et indigeste je vous prévins :
L’invention concerne des procédés, des systèmes et un appareil, y compris des programmes informatiques codés sur des supports de stockage informatique pour entraîner un modèle d’apprentissage automatique à exécuter plusieurs tâches d’apprentissage automatique à partir de plusieurs domaines d’apprentissage automatique. Un système comprend un modèle d’apprentissage automatique qui comprend de multiples réseaux neuronaux de modalité d’entrée correspondant à différentes modalités respectives et étant configuré pour mapper les entrées de données reçues de la modalité correspondante à des entrées de données mappées à partir d’un espace de représentation unifié; un réseau neuronal de codeur configuré pour traiter des entrées de données mappées à partir de l’espace de représentation unifié pour générer des sorties de données de codeur respectives; un réseau neuronal de décodeur configuré pour traiter les sorties de données de codeur pour générer des sorties de données de décodeur respectives à partir de l’espace de représentation unifié;et de multiples réseaux neuronaux de modalité de sortie correspondant à différentes modalités respectives et étant configurés pour mapper les sorties de données de décodeur sur les sorties de données de la modalité correspondante.
Plus simple, MUM est un modèle de langage construit sur le même système de transformateur que BERT, qui a fait des vagues en 2019. BERT est un modèle de langage puissant qui a fait une percée lors de sa sortie. MUM, cependant, fait monter les enchères: selon Google, il est censé être 1000 fois plus puissant que BERT.
Une grande partie de ce pouvoir vient du fait qu’il peut effectuer plusieurs tâches à la fois. Il n’a pas à faire une tâche après l’autre, mais il peut gérer plusieurs tâches simultanément.
Cela signifie qu’il peut lire du texte, comprendre le sens, acquérir des connaissances approfondies sur le sujet, utiliser la vidéo et l’audio pour renforcer et enrichir cela, obtenir des informations dans plus de 75 langues et traduire ces résultats en un contenu multicouche qui répond à des questions complexes. Tout à la fois!
Une idée de la puissance de Google MUM
Lors de I / O 2021, Prabhakar Raghavan de Google a donné un aperçu de la façon dont cela fonctionnerait. Il a utilisé la requête complexe «J’ai parcouru le Mt. Adams et maintenant je veux faire une randonnée sur le Mt. Fuji l’automne prochain, que dois-je faire différemment pour me préparer? » pour démontrer ce que MUM pourrait faire. Dans une session de recherche régulière, vous devrez rechercher vous-même tous les différents aspects. Une fois que vous avez tout, vous devez le combiner pour avoir toutes les réponses aux questions.
Maintenant, MUM combinerait des informations provenant de nombreuses sources différentes sur de nombreux aspects différents de la recherche, de la mesure des montagnes à la suggestion d’un imperméable, car c’est la saison des pluies sur le Mt. Fuji et même à l‘extraction des informations de sources japonaises. Après tout, il y a beaucoup plus d’écrits sur ce sujet spécifique dans cette langue.

Dans des requêtes complexes comme celle-ci, tout se résume à combiner des entités, des sentiments et une intention pour comprendre ce que signifie quelque chose. Les machines ont du mal à comprendre le langage humain, et les modèles de langage comme BERT et MUM s’en rapprochent vraiment.
MUM va encore plus loin en traitant le langage et en ajoutant de la vidéo et des images car il est multimodal. Cela permet de générer un résultat riche qui répond à la requête en présentant un tout nouveau contenu. MUM sera même intégré à Google Lens, vous pouvez donc pointer votre appareil photo vers vos chaussures de randonnée et demander si celles-ci sont adaptées pour faire cette randonnée jusqu’au Mt. Fuji!
Bien sûr, l’objectif final de tout cela est de vous aider à obtenir plus d’informations avec moins de requêtes de recherche – probablement dans les limites de Google lui-même. Nous avons constaté une augmentation constante des résultats riches et des réponses rapides, qui deviennent également plus visuelles et plus visibles de jour en jour. De nombreux autres développements, à la fois à l’intérieur et à l’extérieur de la recherche, brossent l’image d’un Google qui cherche à fournir lui-même la plupart des réponses à vos questions.
Sur la voie d’une recherche conversationnelle et visuelle entièrement alimentée par l’AI
Google se dirige ouvertement vers un moteur de recherche entièrement alimenté par l’AI. Un moteur de recherche n’est même pas le mot juste ici, car il s’agit plutôt d’une machine de présentation de connaissances. Et cela ne se passe pas dans le vide de cette fameuse barre de recherche.
De plus en plus, Google ouvre l’idée de la recherche pour inclure des entrées provenant de nombreuses autres sources, à savoir:
- Microphones
- Caméras
- Téléviseurs
- Appareils portables
- Haut-parleurs intelligents
Pour servir toutes ces différentes cibles d’une manière qui a du sens sur ces machines, la recherche et la présentation de la recherche doivent changer. Un microphone sur votre tracker de fitness doit entendre et comprendre votre requête, tandis que l’assistant doit faire quelque chose avec et répondre avec quelque chose d’utile.
La compréhension du langage est essentielle. Le développement de modèles de langage ultra-puissants, efficaces et flexibles qui peuvent générer du contenu pour fournir ces réponses de manière succincte et naturelle deviendra essentiel.
À I / O 2021, nous en avons vu un autre exemple: LaMDA.
LaMDA: modèle de langage pour les applications de dialogue
LaMDA, ou modèle de langage pour les applications de dialogue, est un autre grand tour de tête de l’AI dans la keynote I / O 2021 de Google. Il s’agit d’une nouvelle technologie pour communiquer avec une AI – comme un chatbot – beaucoup plus naturellement.
Il peut converser d’une manière plus fluide que les AI précédentes, car celles-ci suivent souvent un chemin simple de A à B. Les chatbots sont facilement confus lorsque vous changez de sujet, par exemple.
LaMDA entreprend de résoudre ce problème. Le modèle peut acquérir une grande quantité de connaissances sur un sujet et s’engager dans un dialogue bidirectionnel complet, même s’il s’aventure en dehors du sujet d’origine.
Google a montré une démonstration d’un modèle LaMDA formé sur la connaissance de la planète Pluton pour en discuter avec l’un des chercheurs. Ce n’est pas parfait, mais cela donne une bonne idée du genre d’avenir auquel nous pouvons nous attendre.
Les questions qui vont forcément surgir
Tous ces développements soulèvent des questions, bien sûr. Par exemple, si Google peut vraiment lire, entendre et voir du contenu dans toutes les langues et le reconditionner dans un nouveau format – avec le contexte et le contenu généré par l’AI – qui en est le propriétaire? Et qui est responsable de ce que contiennent ces résultats automatisés? Est-ce un autre clou dans le cercueil pour les producteurs de contenu?
Et qu’en est-il des préjugés dans l’AI? Les préjugés et l’éthique sont des sujets énormes dans l’AI, et si nous parlons vraiment d’étapes vers un avenir propulsé par l’AI, nous devons être assurés de sa neutralité et de sa fiabilité.
Bien sûr, Google mentionne spécifiquement le biais de l’AI dans son article et continue de former le modèle. C’est bon à savoir, mais on se demande jusqu’où cela va – et qui va contrôler les observateurs?
Google met MUM à l’épreuve
Google teste actuellement MUM et continuera de le faire avant d’être sûr de son fonctionnement et de l’ajouter aux systèmes par la suite. Il n’y a pas de calendrier précis pour savoir quand cela se fera, mais dans le cas de BERT, ça n’a pas beaucoup trainé.
L’introduction de MUM pourrait simplement signifier de meilleurs résultats de recherche. Néanmoins, cela pourrait également signifier un nouveau type de résultat de recherche où la part déjà importante des contenus automatisés issus du kwowledge graph serait encore plus prépondérante au détriment des véritables éditeurs de contenus. Car après tout, MUM se nourrira du travail des hommes, MUM ne pense pas, n’invente pas, ne créé pas, il compile de manière industrielle le travail laborieux des hommes.
Lire aussi:


















